DataTig helps you crowd source data in a git repository

Introduction
Do you want to crowdsource data from people? These data exercises are often referred to as “mapping”, and I’ve previously blogged about things to think about when planning such an project.
There are many different ways to do this technically and manage the data. One of them is to store the data in a git repository, and invite people to contribute by making pull requests.
If you are interested in doing so then read on as I introduce DataTig, a project to do just that.
It makes the data you produce as useful as possible, and makes the contribution process as easy as possible.
Wait, would people actually do this?
They already do.
I work on open data projects at Open Data Services, a workers co-operative. One of these projects is Org-id - a list of registers that list organisations.
Org-id helps us unambiguously refer to organisations by creating open, unique identifiers. We use these identifiers in our work on data standards. For example, when someone publishes data using a standard like Open Contracting Data Standard or Beneficial Ownership Data Standard and they want to refer to an organisation, it’s best if they do so using a common list. That means you can take data from 2 different publishers and compare the data sets quickly. (This is a brief explanation of why Org-id is a good thing; we’ve written more about identifiers on the Open Data Services blog).
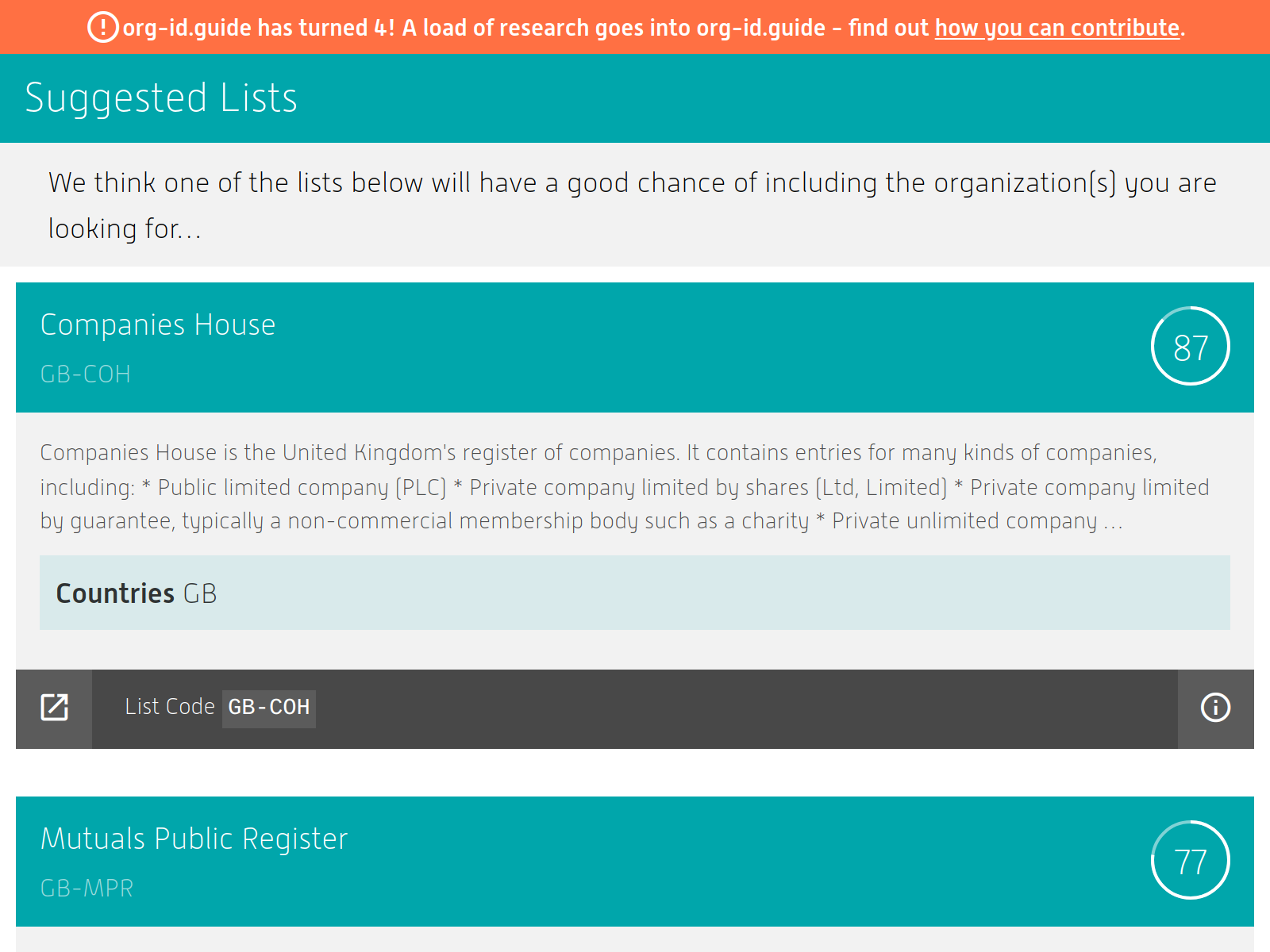
The point is, the data for this is stored in a git repository and contributions are made and reviewed by pull request.
Or what about Netlify themselves? They run a website listing over 300 static site generators.
Or there is Code For IATI, a website listing projects that work with the IATI data standard. (Their data is here.)
Or there is Up For Grabs, a website listing open source projects which have curated tasks specifically for new contributors. (Their data is here.)
EDIT: I've just seen that this month GitHub started doing the same thing with their Advisory Database.
I could go on but hopefully you get the message - people really do crowdsource data in git. Which is why I wanted to work on DataTig. I saw a real user need here (including our own need) and I saw that a tool could really help the people who are already doing this.
So what is DataTig and how does it help?
DataTig is a Python tool. You drop a configuration file in your git repository and then the tool comes to life.
DataTig is a static site builder to help people use the data
The tool will build a static site for you. You can see the static site it makes for org-id here. This site does many things …
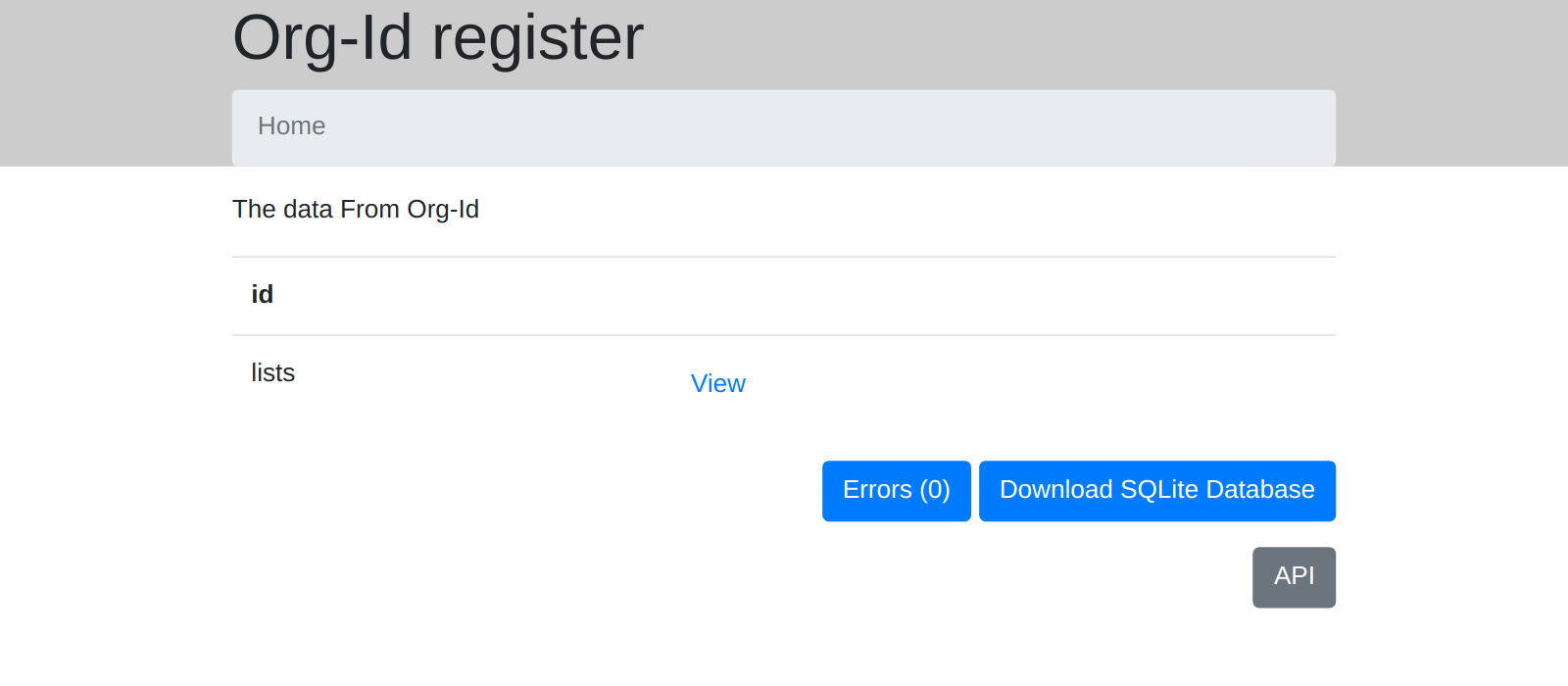
It displays the data in a way that is easy for humans to browse and read.
It also publishes the data in a way that is easy for other computers to read - an API essentially. It publishes a JSON API. It also publishes a SQLIte database of all the data that you can download and run your queries against straight away.
DataTig is a static site builder to help people contribute data
Let’s say you want to contribute data. Sure, a programmer can edit a file directly and make a pull request - but that’s a bit of a barrier. Some less technical people won’t be happy doing this.
So DataTig makes a form where you can edit the data in your browser - here’s an example:
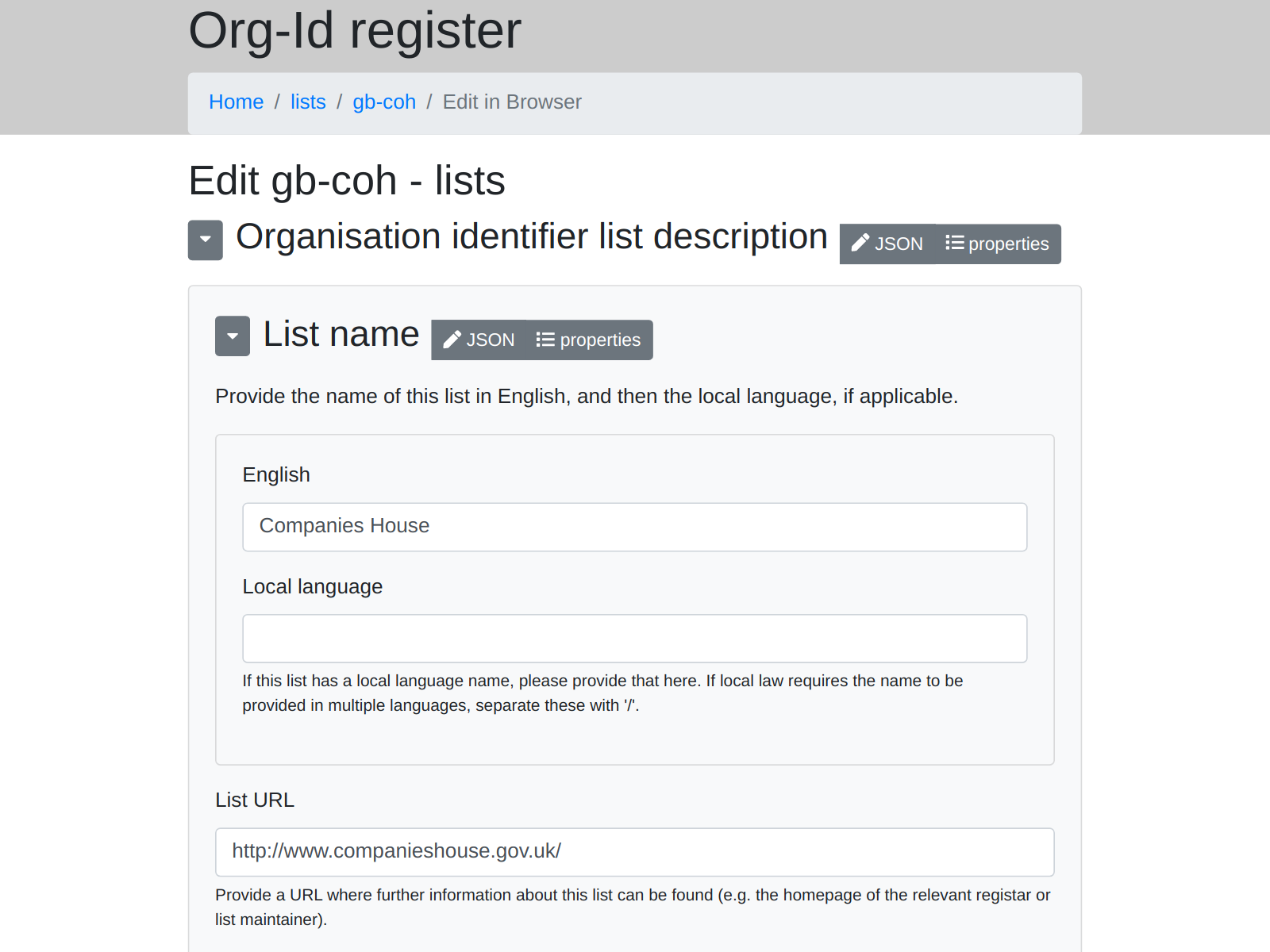
It can’t yet make the pull request for you, but that’s a feature I am hoping to add soon. However it can provide instructions on how to go to GitHub and make the pull request yourself:
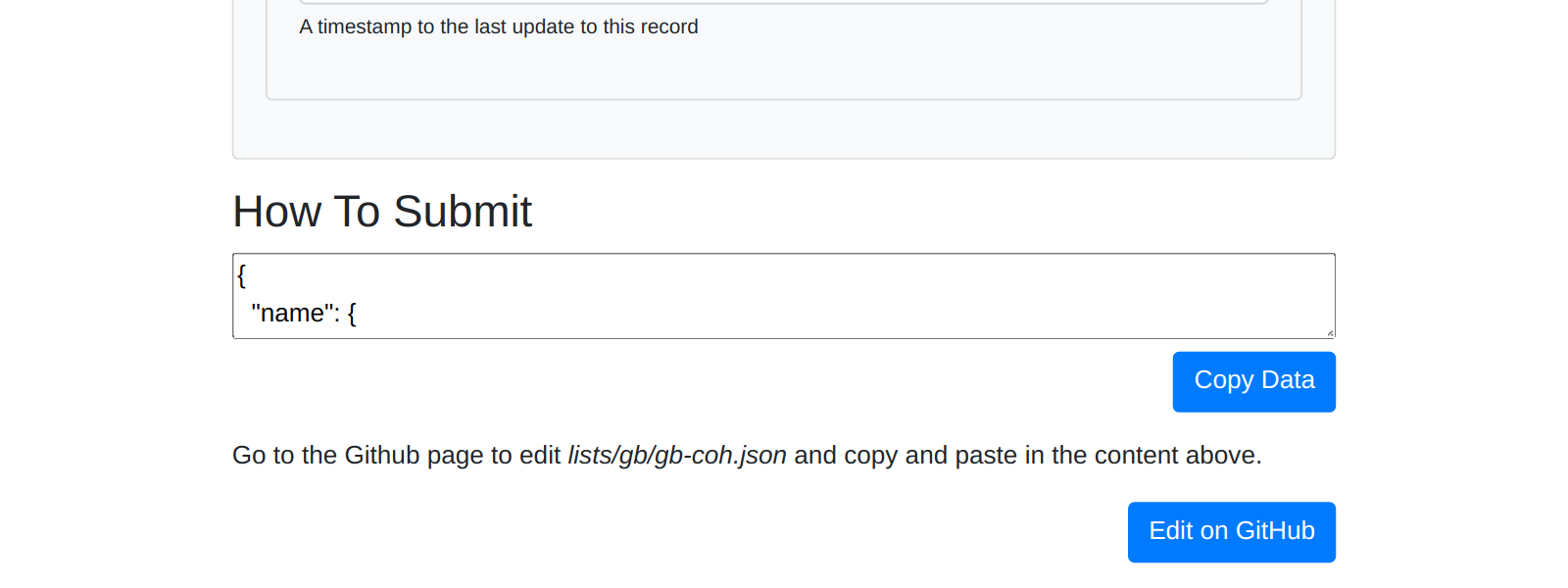
DataTig checks the data is correct
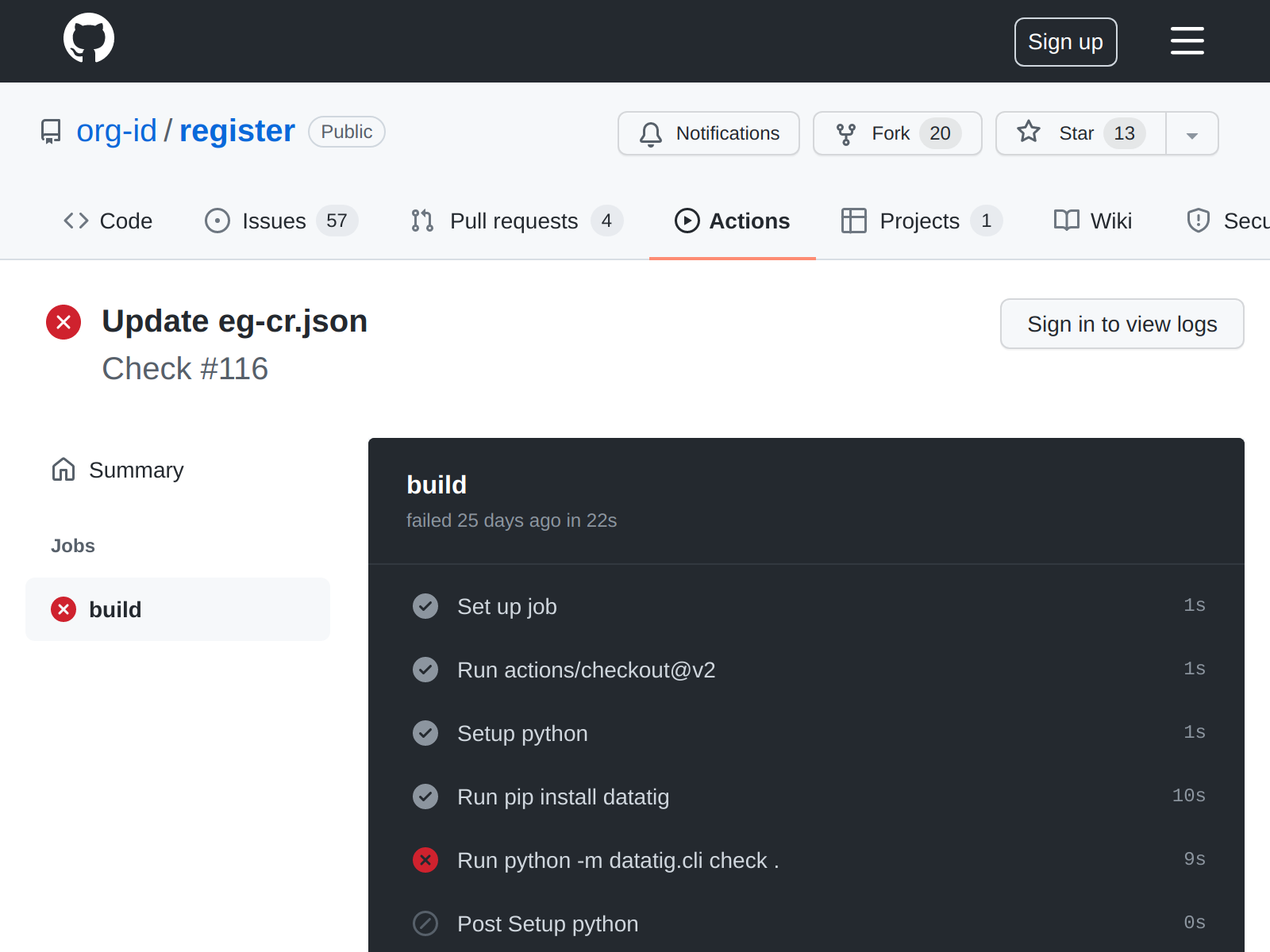
The tool can check the structure and format of your data for you and report on errors - for instance, see this entry on Org-id and it’s errors.
These errors are listed in the static site, both for humans to read and for computers to read.

It also has a mode where you can run this in your C.I. server - so anytime someone tries to contribute data to your site DataTig can run and tell you if the data is structured correctly.
But the user experience is more functional than pretty?
Yup, fair point. But I don’t envisage our UI being the main way that people will interact with the data. I think people will want to make their own front end sites to show their data off. (I’ve listed such sites above - Org-id Guide, Jamstack, CodeForIati and Up For Grabs)
But before you can do this, you have to collect all the data out of your git repository and check it is correct. Here’s where DataTig can help - instead of every project writing this code from scratch, they can just use DataTig to do that! DataTig produces SQLite databases or JSON files that can then be used in other developers' apps.
And you probably want to make it easier for people to contribute data. Again, there’s no need for each project to do this from scratch - DataTig can help.
What’s next?
It’s still early days for DataTig, but already this MVP has demonstrated its usefulness by making life easier for people working on data for Org-id.
I am going to keep developing it with more features - I have lots more ideas:
- Ways to make setting up DataTig easier.
- More ways to publish the data so it’s even more useful.
- Better ways to allow people to contribute data so there is even less of a technical barrier.
- Better tools to help people check the data is correct.
- Better tools to help people keep the data up to date by highlighting old data.
- Better tools to help people view the history of the data.
I’ve blogged before about what you have to think about to run good data mapping projects, and I really think in some cases DataTig could help that.
DataTig with Netlify
DataTig can be treated as a static site builder and used with Netlify. Then you get all the benefits of Netlify - builds automatically attached to pull requests, for instance.
It’s really easy to set up - you just need to add to your repository:
That’s it! Now sign up for your Netlify account and create your app.
The Code
Best practises
When Open Data Services write Python we try to follow best practices. We use black, isort and flake8 to lint our code. We try to follow PEP8 naming patterns. We write tests in Pytest. All this was done for DataTig.
But also for the first time I tried using strongly typed Python and mypy to type check my code. I also develop in modern PHP and I’ve developed Java for Android applications, so the idea of a strongly typed language wasn’t new to me. I agree with the idea that a good strongly typed language is much more help than hindrance to a programmer and I was really curious to see how this works in Python. I found that mypy made me be clearer about what my code was doing, and was a help.
Using SQLite
Sqlite is a database engine, but one that needs no server. It creates a single file to hold all the data, and that file can be worked with directly from many tools and programming languages. This creates some limitations to its use that a traditional engine like Postgresql wouldn’t have - but it also creates many new opportunities. Like most things in development, it’s not that one database is always better than another but that they have different uses and it’s important to pick the best tool for your current needs.
How does the internals of our code work? There are essentially several steps.
- Load the DataTig configuration setup from the repository
- Create an SQLite database
- Load all the actual data from the repository straight into the SQLite database. Check for errors in the data as you do, and log any in the database.
- Build the Static site by loading data from the SQLite database.
Using SQLite in this way makes for a more memory efficient process, as you don’t have to hold all the data in memory at once. SQLite also has minimal requirements which means the tool can run in static site builders like Netlify (that wouldn’t have been true if I had used something like Postgresql). And it’s a really neat feature that people can just download the SQLite database file to quickly and easily start using the data themselves.
Using JSON Schema
JSON is a data format that we heavily use. Whether the files in your repository are JSON, Markdown or YAML files, when we load them we convert them to JSON format.
But how do you make sure that the data in your JSON file is the correct structure?
{
"title": "Bad Data Record",
"tags": [
"this tag list is meant to be strings only",
[
" a list within a list when it's meant to be a string! oh no!"
],
{
"data": "a dict is also bad"
}
]
}
For this we heavily use JSON Schema. This is a tool that lets you specify what the structure of the data should be; for example, tags should be a list of strings only and not other types.
We use this for error checking - there are good Python libraries that will check your JSON data against a JSON Schema and log any errors.
We also use this for our data entry forms - there is a Javascript library that will take your JSON Schema and build a form for you.
Thanks to these Open Source libraries we managed to add some complex functionality to DataTig with very little work.
What I did for the hackathon
Early work on DataTig to release some first versions began before February – but I used the Hackathon to focus on releasing a new version as an MVP. This new version:
- Makes it simpler to set up a DataTig site properly. (Because of that, I could rewrite the tutorial to make that simpler too.)
- Allows people to put data in Markdown files.
- Adds more information to the static site - it now has an JSON API so that others can reuse the data.
- Adds more information to the static site - the SQLite database now has more columns and tables so that others can reuse the data.
- Adds a new field type for a list of strings - this is often used for tags by people.
- Adds more options for static site building.
You can see the full changelog here.
That’s it! Find out more or get in touch
The tool is on PyPi, and it has documentation online with a tutorial for new starters. The code is on GitHub.
I hope you like it – get in touch with any questions (my email is in my profile).